

Every type of research includes samples from which inferences are drawn. The sample could be biological specimens or a subset of a specific group or population selected for analysis. The goal is often to conclude the entire population based on the characteristics observed in the sample. Now, the question comes to mind: how does one collect the samples? Answer: Using sampling methods. Various sampling strategies are available to researchers to define and collect samples that will form the basis of their research study.
In a study focusing on individuals experiencing anxiety, gathering data from the entire population is practically impossible due to the widespread prevalence of anxiety. Consequently, a sample is carefully selected—a subset of individuals meant to represent (or not in some cases accurately) the demographics of those experiencing anxiety. The study’s outcomes hinge significantly on the chosen sample, emphasizing the critical importance of a thoughtful and precise selection process. The conclusions drawn about the broader population rely heavily on the selected sample’s characteristics and diversity.
Table of Contents
Sampling involves the strategic selection of individuals or a subset from a population, aiming to derive statistical inferences and predict the characteristics of the entire population. It offers a pragmatic and practical approach to examining the features of the whole population, which would otherwise be difficult to achieve because studying the total population is expensive, time-consuming, and often impossible. Market researchers use various sampling methods to collect samples from a large population to acquire relevant insights. The best sampling strategy for research is determined by criteria such as the purpose of the study, available resources (time and money), and research hypothesis.
For example, if a pet food manufacturer wants to investigate the positive impact of a new cat food on feline growth, studying all the cats in the country is impractical. In such cases, employing an appropriate sampling technique from the extensive dataset allows the researcher to focus on a manageable subset. This enables the researcher to study the growth-promoting effects of the new pet food. This article will delve into the standard sampling methods and explore the situations in which each is most appropriately applied.
Sampling methods or sampling techniques in research are statistical methods for selecting a sample representative of the whole population to study the population’s characteristics. Sampling methods serve as invaluable tools for researchers, enabling the collection of meaningful data and facilitating analysis to identify distinctive features of the people. Different sampling strategies can be used based on the characteristics of the population, the study purpose, and the available resources. Now that we understand why sampling methods are essential in research, we review the various sample methods in the following sections.
Before we go into the specifics of each sampling method, it’s vital to understand terms like sample, sample frame, and sample space. In probability theory, the sample space comprises all possible outcomes of a random experiment, while the sample frame is the list or source guiding sample selection in statistical research. The sample represents the group of individuals participating in the study, forming the basis for the research findings. Selecting the correct sample is critical to ensuring the validity and reliability of any research; the sample should be representative of the population.
There are two most common sampling methods:
Irrespective of the research method you opt for, it is essential to explicitly state the chosen sampling technique in the methodology section of your research article. Now, we will explore the different characteristics of both sampling methods, along with various subtypes falling under these categories.
The probability sampling method is based on the probability theory, which means that the sample selection criteria involve some random selection. The probability sampling method provides an equal opportunity for all elements or units within the entire sample space to be chosen. While it can be labor-intensive and expensive, the advantage lies in its ability to offer a more accurate representation of the population, thereby enhancing confidence in the inferences drawn in the research.
Various probability sampling methods exist, such as simple random sampling, systematic sampling, stratified sampling, and clustered sampling. Here, we provide detailed discussions and illustrative examples for each of these sampling methods:

For example, A fitness sports brand is launching a new protein drink and aims to select 20 individuals from a 200-person fitness center to try it. Employing a simple random sampling approach, each of the 200 people is assigned a unique identifier. Of these, 20 individuals are then chosen by generating random numbers between 1 and 200, either manually or through a computer program. Matching these numbers with the individuals creates a randomly selected group of 20 people. This method minimizes sampling bias and ensures a representative subset of the entire population under study.

For example, considering the previous model, individuals at the fitness facility are arranged alphabetically. The manufacturer then initiates the process by randomly selecting a starting point from the first ten positions, let’s say 8. Starting from the 8th position, every tenth person on the list is then chosen (e.g., 8, 18, 28, 38, and so forth) until a sample of 20 individuals is obtained.

For example, Expanding on the previous simple random sampling example, suppose the manufacturer aims for a more comprehensive representation of genders in a sample of 200 people, consisting of 90 males, 80 females, and 30 others. The manufacturer categorizes the population into three gender strata (Male, Female, and Others). Within each group, random sampling is employed to select nine males, eight females, and three individuals from the others category, resulting in a well-rounded and representative sample of 200 individuals.

For example, Researchers conducting a nationwide health study can select specific geographic clusters, like cities or regions, instead of trying to survey the entire population individually. Within each chosen cluster, they sample individuals, providing a representative subset without the logistical challenges of attempting a nationwide survey.
Probability sampling methods find widespread use across diverse research disciplines because of their ability to yield representative and unbiased samples. The advantages of employing probability sampling include the following:
Probability sampling assures that every element in the population has a non-zero chance of being included in the sample, ensuring representativeness of the entire population and decreasing research bias to minimal to non-existent levels. The researcher can acquire higher-quality data via probability sampling, increasing confidence in the conclusions.
Statistical methods, like confidence intervals and hypothesis testing, depend on probability sampling to generalize findings from a sample to the broader population. Probability sampling methods ensure unbiased representation, allowing inferences about the population based on the characteristics of the sample.
The use of probability sampling improves the precision and reliability of study results. Because the probability of selecting any single element/individual is known, the chance variations that may occur in non-probability sampling methods are reduced, resulting in more dependable and precise estimations.
Probability sampling enables the researcher to generalize study findings to the entire population from which they were derived. The results produced through probability sampling methods are more likely to be applicable to the larger population, laying the foundation for making broad predictions or recommendations.
By ensuring that each member of the population has an equal chance of being selected in the sample, probability sampling lowers the possibility of selection bias. This reduces the impact of systematic errors that may occur in non-probability sampling methods, where data may be skewed toward a specific demographic due to inadequate representation of each segment of the population.

Non-probability sampling methods involve selecting individuals based on non-random criteria, often relying on the researcher’s judgment or predefined criteria. While it is easier and more economical, it tends to introduce sampling bias, resulting in weaker inferences compared to probability sampling techniques in research.
Non-probability sampling methods are further classified as convenience sampling, consecutive sampling, quota sampling, purposive or judgmental sampling, and snowball sampling. Let’s explore these types of sampling methods in detail.
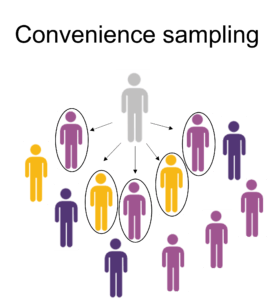
For example, imagine you’re a researcher investigating smartphone usage patterns in your city. The most convenient way to select participants is by approaching people in a shopping mall on a weekday afternoon. However, this convenience sampling method may not be an accurate representation of the city’s overall smartphone usage patterns as the sample is limited to individuals present at the mall during weekdays, excluding those who visit on other days or never visit the mall.
For example, In researching the prevalence of stroke in a hospital, instead of randomly selecting patients from the entire population, the researcher can opt to include all eligible patients admitted over three months. Participants are then consecutively recruited upon admission during that timeframe, forming the study sample.
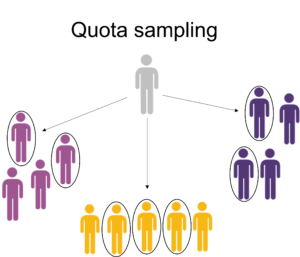
For example, In a survey on a college campus to assess student interest in a new policy, the researcher should establish quotas aligned with the distribution of student majors, ensuring representation from various academic disciplines. If the campus has 20% biology majors, 30% engineering majors, 20% business majors, and 30% liberal arts majors, participants should be recruited to mirror these proportions.

For example, imagine a researcher who wants to study public policy issues for a focus group. The researcher might purposely select participants with expertise in economics, law, and public administration to take advantage of their knowledge and ensure a depth of understanding.
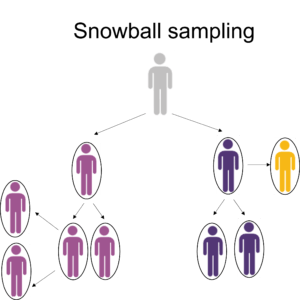
For example, In a study focusing on understanding the experiences and challenges of individuals in hidden or stigmatized communities (e.g., LGBTQ+ individuals in specific cultural contexts), the snowball sampling technique can be employed. The researcher initiates contact with one community member, who then assists in identifying additional candidates until the desired sample size is achieved.
Non-probability sampling approaches are employed in qualitative or exploratory research where the goal is to investigate underlying population traits rather than generalizability. Non-probability sampling methods are also helpful for the following purposes:
In the initial stages of exploratory research, non-probability methods such as purposive or convenience allow researchers to quickly gather information and generate hypothesis that helps build a future research plan.
Qualitative research is usually focused on understanding the depth and complexity of human experiences, behaviors, and perspectives. Non-probability methods like purposive or snowball sampling are commonly used to select participants with specific traits that are relevant to the research question.
Non-probability sampling methods are valuable when resource and time are limited or when preliminary data is required to test the pilot study. For example, conducting a survey at a local shopping mall to gather opinions on a consumer product due to the ease of access to potential participants.

| Characteristics | Probability sampling | Non-probability sampling |
| Selection of participants | Random selection of participants from the population using randomization methods | Non-random selection of participants from the population based on convenience or criteria |
| Representativeness | Likely to yield a representative sample of the whole population allowing for generalizations | May not yield a representative sample of the whole population; poor generalizability |
| Precision and accuracy | Provides more precise and accurate estimates of population characteristics | May have less precision and accuracy due to non-random selection |
| Bias | Minimizes selection bias | May introduce selection bias if criteria are subjective and not well-defined |
| Statistical inference | Suited for statistical inference and hypothesis testing and for making generalization to the population | Less suited for statistical inference and hypothesis testing on the population |
| Application | Useful for quantitative research where generalizability is crucial | Commonly used in qualitative and exploratory research where in-depth insights are the goal |
R Discovery is a literature search and research reading platform that accelerates your research discovery journey by keeping you updated on the latest, most relevant scholarly content. With 250M+ research articles sourced from trusted aggregators like CrossRef, Unpaywall, PubMed, PubMed Central, Open Alex and top publishing houses like Springer Nature, JAMA, IOP, Taylor & Francis, NEJM, BMJ, Karger, SAGE, Emerald Publishing and more, R Discovery puts a world of research at your fingertips.
Try R Discovery Prime FREE for 1 week or upgrade at just US$72 a year to access premium features that let you listen to research on the go, read in your language, collaborate with peers, auto sync with reference managers, and much more. Choose a simpler, smarter way to find and read research – Download the app and start your free 7-day trial today !